Exhausted from lack of sleep all week long. For some reason I wake up at 9 every day.
Today we discussed a lot about the user interface of the server we want to use. I think we ended up agreeing on a nice technical approach that will be very good from a UI point of view. It'll be so much fun to implement a technically very complex system of combining UI from all sorts of places into a nice consistent interface. And all code will be sent on the fly over the wire, and cached. Stuff like that is just so easy to do in Python.
Afterwards, Ronald arrived. He seems happy to be working on GStreamer for us, which is great ! I hope we can still get Totem in FC3.
Then, office party. We were still checking Christian's SlashDot submission about our article and applet. It had been pending for over a day. Still no dice.
After that, out for a very nice dinner at the Bestial with the team. I wanted to go home quick to finally get a nice early night to go to bed.
So I browse some stuff, check if the stream is still running, do some more things, and do one final check to see if the firewire is not complaining. Network down. Damn crap router acting up again. Still, decide to wait, because I'm anal-retentive and I really always think that "you might never now if it hit some site and we have traffic". Reload admin page. 200 people. Blink. Check Slashdot. OMG. It's on. Click reload on admin page. 400 people.
Start calling collagues. Do a short dance. 600 people. Server hanging in nicely. Unplug machine from home network that resets the router every 20 minutes so I have good connection for the rest of the night while I do stuff.
Read someone saying on Slashdot that "there is no sound". Damn, remember that I had turned off the sound for the discussions this afternoon. Fire up the user interface for the administration, go to the producing component, and set the volume level to 50%. Sound is fine now.
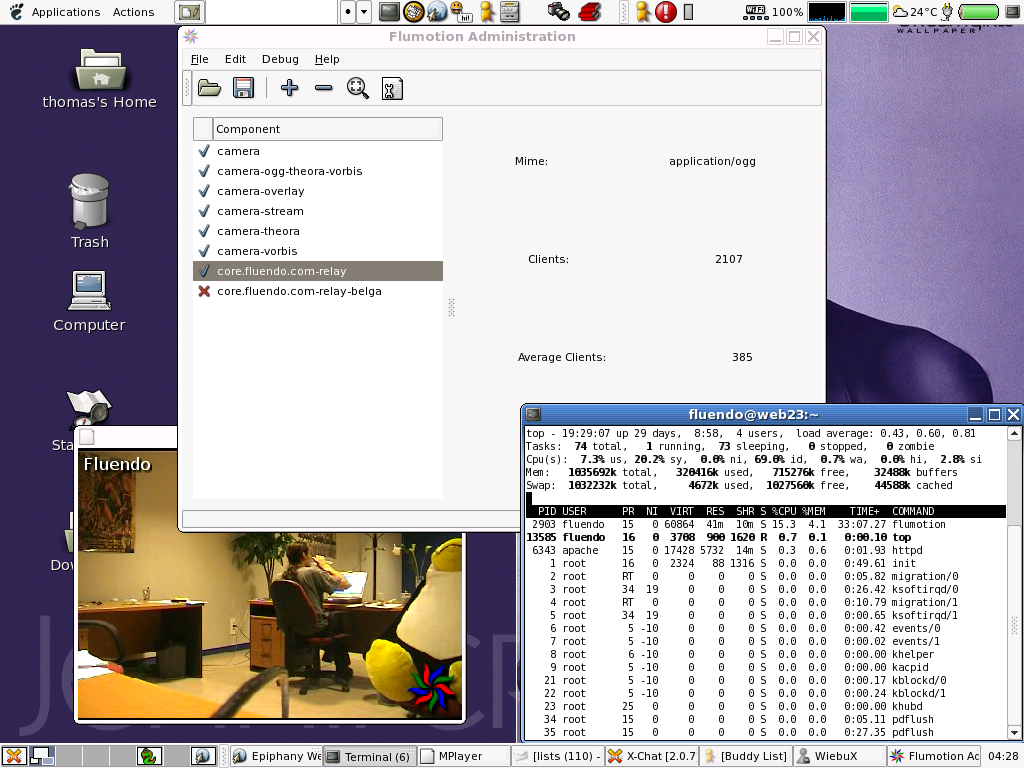
Call friend in Belgium. "Can I have your bandwidth, some access, and transfer our shiny new server so I can relay ?". Lots of fiddling to try and set up in FC1 ( we need python 2.3). Install mach, set up an FC2 root. Install stuff. Test server. Start server with relay config. New streamer pops up in my UI immediately on my local machine, and I can see how many people are connected. Awesome.
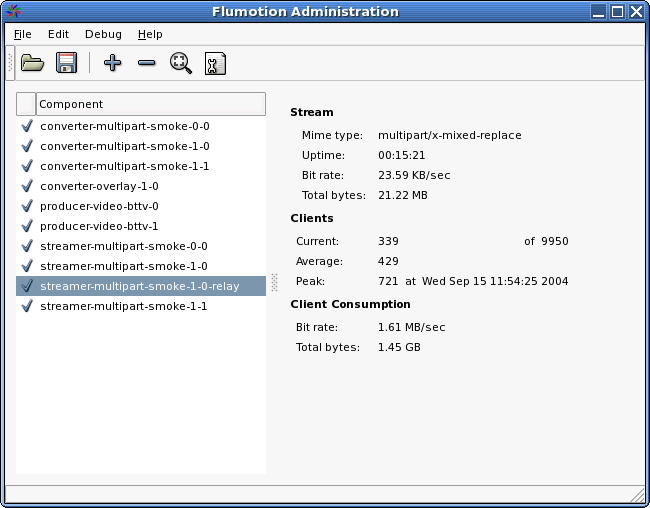
Here's a screenshot I took from the UI I'm using to control the server (Don't worry, just a quick prototype hack, as I said we're still designing the UI ...) You can see that it's handling over 2000 clients, CPU usage on the 800 MHz streaming server is fine, and another relayer (which has a red cross, which is some bug I need to fix) is also streaming to a whole bunch of clients. The main server is maxed out on bandwidth at about 55 Mbit/sec. The second server is getting up to about 700 clients as we speak. I forgot to increase the file descriptor limit on that box, so it wouldn't accept more than 1000, so I had to restart it after tweaking the config.
But, surprisingly (even though I should not say so), the server is holding up great against a Slashdotting.
Wim sums it up nicely:
<wtay> so, the slashdot effects is about 2400 clients.. how lame..
Of course, it's Friday late night, people have gone home, so I expect a steady stream of interest over the weekend. Let's hope the firewire bus doesn't stop working randomly like it sometimes tends to do.
And people seem to like the barebones Java applet a lot as well.
Anyway, four hours later, server still running, I am still desperately lacking sleep, and it's 5 AM. I know I'll regret this tomorrow, but it's been fun. Enough tooting my own horn, back to the weekend.
Exhausted from lack of sleep all week long. For some reason I wake up at 9 every day. Today we discussed a lot about the user interface of the server...
![[lang]](/images/eye.png)
{kind=link}
{kind=link}